
FACTBENCH
arXiv2024-10-30 更新2024-10-31 收录
资源简介:
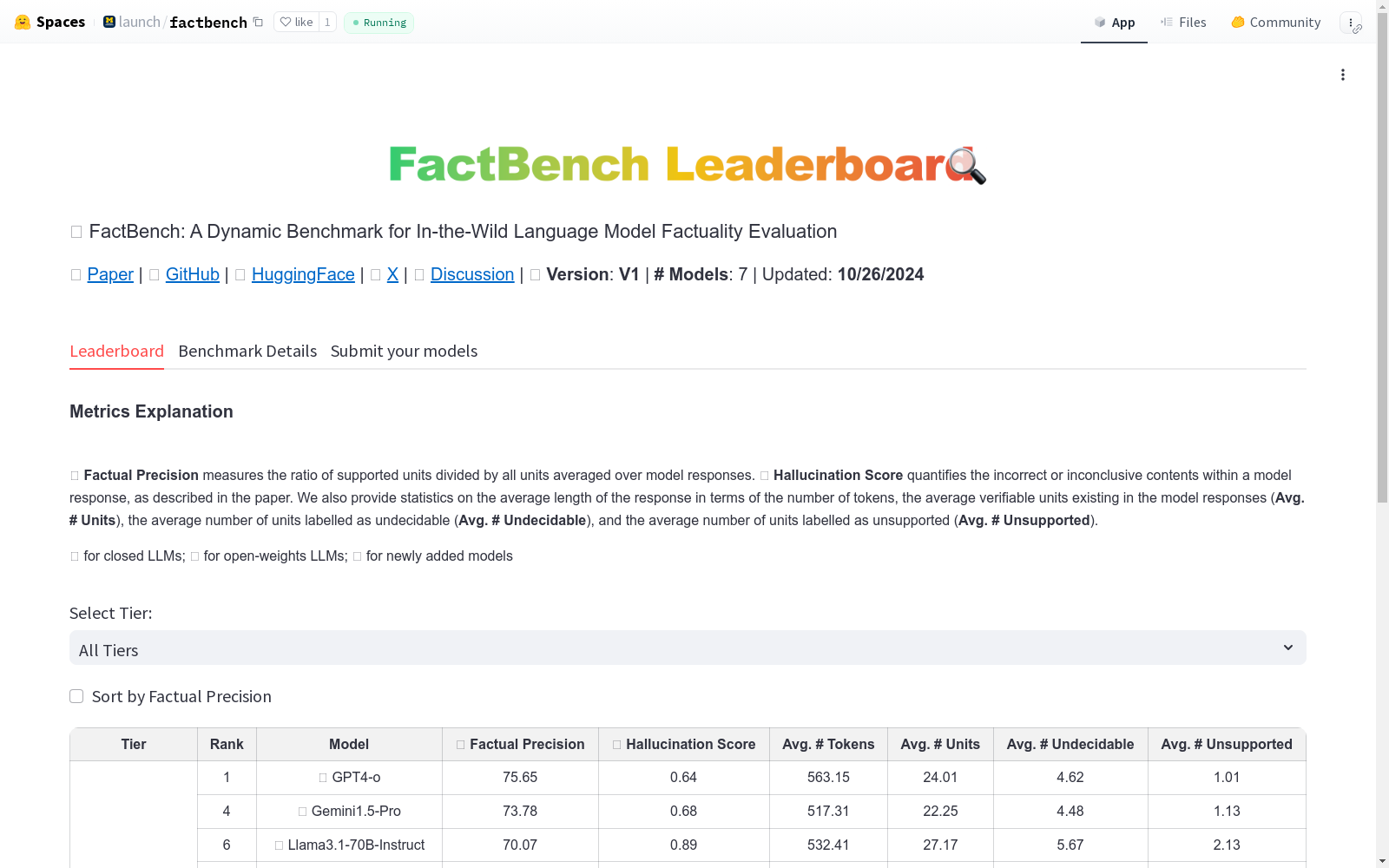
FACTBENCH是由密歇根大学计算机科学与工程系创建的一个动态基准数据集,用于评估语言模型在真实世界交互中的事实性。该数据集包含1000个多样化的信息查询提示,涵盖150个主题,旨在捕捉语言模型在生成错误和不明确响应时面临的挑战。数据集的创建过程包括从LMSYS-Chat-1M数据集中提取提示,并通过VERIFY管道进行验证和分类。FACTBENCH的应用领域主要集中在语言模型的事实性评估,旨在解决模型在处理复杂和多样化查询时可能产生的幻觉问题。
原始地址:
https://huggingface.co/spaces/launch/factbench
提供机构:
密歇根大学计算机科学与工程系
创建时间:
2024-10-30
FactBench 数据集概述
数据集信息
- 许可证: CC BY 4.0
- 版本: 1.0
数据文件
- tier_1:
tier_1.csv - tier_2:
tier_2.csv - tier_3:
tier_3.csv
内容分类
- 支持: 基于检索到的网络证据,内容单元被分类为支持、不支持或无法确定。
- 相关性: VERIFY 的事实判断与人类评估的相关性优于现有方法。
数据集特点
- 幻觉提示: 识别出在不同主题下引发最高错误率或不可验证的 LM 响应的提示。
- 主题覆盖: 数据集包含 985 个提示,涵盖 213 个细粒度主题。
- 更新频率: 数据集定期更新新提示,以捕捉现实世界中 LM 交互中的新兴事实性挑战。
致谢
- Serper 团队: 感谢 Serper 团队提供对 Google Search API 的访问权限,这显著促进了基准的制作并加速了幻觉提示的评估。
数据集介绍
构建方式
FACTBENCH的构建基于VERIFY管道,该管道通过评估语言模型生成内容的可验证性,并根据从网络检索的证据将内容单元分类为支持、不支持或无法决定。研究团队首先从LMSYS-Chat-1M数据集中识别出382个独特的任务,然后对每个任务集群中的提示进行可验证性标记,判断其响应是否可以通过Google搜索结果验证。随后,通过考虑清晰度、兴趣和广泛受众的相关性等因素评估提示的有用性,最终将符合特定有用性阈值的可验证提示纳入FACTBENCH。
使用方法
使用FACTBENCH时,研究者可以通过VERIFY管道对语言模型的响应进行事实性评估,该管道首先提取模型响应中的内容单元,并根据其类型(如事实、声明、指令等)进行分类。然后,仅对可验证的单元进行评估,通过交互式查询生成和证据检索技术,根据检索到的证据将其分类为支持、不支持或无法决定。最终,通过计算幻觉分数来量化模型响应中的错误和不确定内容,从而评估提示的适当性。
背景与挑战
背景概述
FACTBENCH数据集由密歇根大学计算机科学与工程系的Farima Fatahi Bayat、Lechen Zhang、Sheza Munir和Lu Wang等人创建,旨在评估语言模型在实际应用中的事实性。该数据集于2024年推出,通过VERIFY管道识别并分类语言模型生成的内容,将其分为支持、不支持或无法确定三类。FACTBENCH包含1000个跨150个细粒度主题的提示,捕捉了语言模型在实际交互中面临的最新事实性挑战,并可定期更新以保持其相关性。该数据集对语言模型的事实性评估具有重要影响,特别是在识别和解决模型在处理复杂和多样化主题时产生的幻觉问题。
当前挑战
FACTBENCH数据集面临的挑战主要集中在两个方面:一是解决语言模型在实际应用中生成错误或无关内容的问题,即所谓的幻觉问题;二是构建过程中遇到的挑战,包括如何从大规模的实际对话数据中有效提取和分类可验证的提示,以及如何确保数据集的动态更新以反映语言模型能力的不断演变。此外,数据集还需要应对现有评估基准的静态性和覆盖范围狭窄的问题,确保其能够全面捕捉语言模型在实际使用中的事实性挑战。
常用场景
经典使用场景
FACTBENCH 数据集的经典使用场景在于评估语言模型在真实世界用户交互中的事实性。通过收集和分析大量多样化的用户提示,该数据集能够识别出那些容易引发模型生成错误或不确定响应的提示,从而为模型的实际应用提供有价值的反馈。
解决学术问题
FACTBENCH 数据集解决了当前语言模型评估中存在的静态和狭窄覆盖问题。它通过动态更新和广泛的主题覆盖,提供了一个更加真实和全面的评估基准,有助于识别模型在实际应用中面临的事实性挑战,推动语言模型在事实性生成方面的研究进展。
实际应用
FACTBENCH 数据集在实际应用中主要用于语言模型的开发和优化。开发者可以利用该数据集进行模型的调试和改进,确保模型在面对复杂和多样化的用户查询时能够生成准确和可靠的响应。此外,该数据集还可用于模型的持续监控和更新,以适应不断变化的信息环境。
数据集最近研究
最新研究方向
FACTBENCH数据集的最新研究方向聚焦于动态评估语言模型在实际应用中的事实性。研究者们通过引入VERIFY管道,对模型生成内容进行验证和证据检索,从而更准确地评估模型的事实性。该方法不仅考虑了内容的可验证性,还将内容单元分类为支持、不支持或无法决定,从而提高了与人类评估的相关性。此外,FACTBENCH数据集通过捕捉真实世界交互中的新兴事实性挑战,定期更新提示,确保了基准的持续相关性和实用性。
相关研究论文
- 1FactBench: A Dynamic Benchmark for In-the-Wild Language Model Factuality Evaluation密歇根大学计算机科学与工程系 · 2024年
以上内容由AI搜集并总结生成
相关数据集

未查询到数据集