
EusParallel
huggingface2024-10-30 更新2024-12-12 收录
资源简介:
EusParallel是一个包含英语、西班牙语和巴斯克语的多平行文档级语料库。巴斯克语文档由人工编写,而英语和西班牙语文本则是通过机器翻译从巴斯克语翻译而来,使用了`meta-llama/Meta-Llama-3-70B-Instruct`模型。该语料库旨在训练高质量的机器翻译模型,能够将文档从英语和西班牙语翻译成巴斯克语。文档长度在10到4096个token之间,使用了`meta-llama/Meta-Llama-3-70B-Instruct`的tokenizer进行计算。翻译过程中使用了特定的提示和超参数设置,并在8个A100 80GB GPU上使用vLLM推理引擎进行计算。
原始地址:
https://huggingface.co/datasets/HiTZ/EusParallel
提供机构:
HiTZ zentroa
创建时间:
2024-10-30
EusParallel 数据集概述
数据集信息
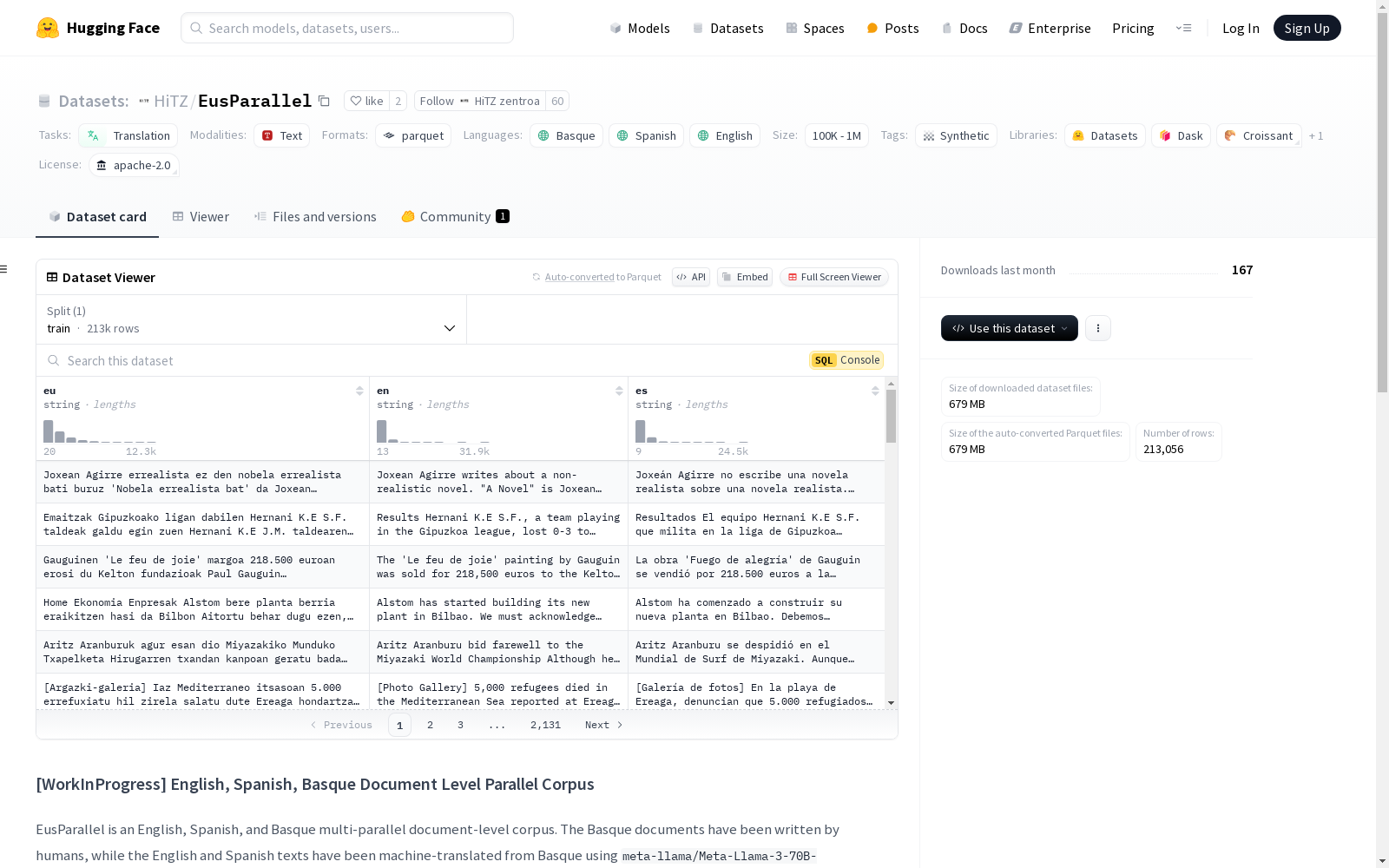
- 特征:
eu: 巴斯克语文本,类型为字符串。en: 英语文本,类型为字符串。es: 西班牙语文本,类型为字符串。
- 分割:
train: 训练集,包含213056个样本,总大小为1125766276字节。
- 下载大小: 679317566字节
- 数据集大小: 1125766276字节
- 配置:
default: 默认配置,数据文件路径为data/train-*。
- 许可证: Apache 2.0
- 任务类别: 翻译
- 语言: 巴斯克语、英语、西班牙语
- 标签: 合成数据
数据集详情
- 来源: 巴斯克语文本来自HiTZ/latxa-corpus-v1.1,随机抽取的文档。
- 翻译模型: 使用
meta-llama/Meta-Llama-3-70B-Instruct进行机器翻译。 - 文档长度: 每个文档包含10到4096个token。
- 超参数:
- 模型:
meta-llama/Meta-Llama-3-70B-Instruct - 温度:
0.15 - Top_p:
0.1 - 最大新token数:
4096 - 数据类型:
bfloat16
- 模型:
- 提示:
- 英语系统提示: 要求模型将巴斯克语文本翻译为英语,仅提供翻译结果。
- 西班牙语系统提示: 要求模型将巴斯克语文本翻译为西班牙语,仅提供翻译结果。
- 计算资源: 使用8个A100 80GB GPU和vLLM推理引擎进行计算,张量并行度为8。
脚本
- Python代码: translate.py
- Slurm启动脚本: 用于Hyperion系统。
数据集介绍
构建方式
EusParallel数据集是一个多语言平行语料库,包含巴斯克语、英语和西班牙语的文档级翻译对。巴斯克语文档由人工撰写,而英语和西班牙语文本则通过`meta-llama/Meta-Llama-3-70B-Instruct`模型从巴斯克语机器翻译生成。数据集的构建过程包括从[HiTZ/latxa-corpus-v1.1]中随机抽取巴斯克语文档,并使用特定的翻译提示和参数进行机器翻译。翻译过程在8xA100 80GB GPU上完成,采用vLLM推理引擎进行高效计算。
特点
EusParallel数据集的特点在于其多语言平行性,涵盖了巴斯克语、英语和西班牙语三种语言。巴斯克语文档为人工撰写,确保了源语言的质量,而英语和西班牙语文本则通过先进的`meta-llama/Meta-Llama-3-70B-Instruct`模型进行翻译,保证了翻译的准确性和上下文一致性。数据集中的文档长度在10到4096个标记之间,适合用于训练高质量的机器翻译模型。
使用方法
EusParallel数据集主要用于训练和评估机器翻译模型,特别是针对巴斯克语与英语、西班牙语之间的翻译任务。用户可以通过HuggingFace平台下载数据集,并利用提供的Python脚本和Slurm启动脚本来复现翻译过程。数据集的结构清晰,包含训练集,可直接用于模型训练。此外,用户可以根据需要调整翻译参数,以优化翻译效果。
背景与挑战
背景概述
EusParallel数据集是一个多语言平行语料库,涵盖英语、西班牙语和巴斯克语,旨在为高质量机器翻译模型的训练提供支持。该数据集由巴斯克语的人类撰写文本以及通过`meta-llama/Meta-Llama-3-70B-Instruct`模型机器翻译的英语和西班牙语文本构成。巴斯克语文本来源于[HiTZ/latxa-corpus-v1.1](HiTZ/latxa-corpus-v1.1)语料库,每篇文档包含10至4096个token。该数据集的创建旨在解决巴斯克语与其他语言之间的翻译问题,特别是在文档级别翻译中的应用。通过使用先进的机器翻译模型,EusParallel为巴斯克语的自然语言处理研究提供了重要资源。
当前挑战
EusParallel数据集在构建和应用过程中面临多重挑战。首先,巴斯克语作为一种孤立语言,其语法和词汇结构与其他语言差异显著,这增加了翻译的复杂性,尤其是在保持语义和上下文一致性方面。其次,尽管使用了先进的`meta-llama/Meta-Llama-3-70B-Instruct`模型进行机器翻译,但翻译质量仍可能受到源文本多样性和模型参数设置的影响,例如温度值和top_p参数的调整。此外,数据集的构建依赖于高性能计算资源,如8xA100 80GB GPU,这对计算资源的可用性和成本提出了较高要求。最后,如何确保翻译结果的准确性和流畅性,特别是在长文档翻译中,仍然是一个亟待解决的问题。
常用场景
经典使用场景
EusParallel数据集在机器翻译领域具有重要应用,尤其是在英语、西班牙语和巴斯克语之间的多语言翻译任务中。该数据集通过提供高质量的文档级平行语料,为训练和评估机器翻译模型提供了坚实的基础。研究人员可以利用该数据集进行跨语言翻译模型的训练,特别是在巴斯克语这种资源相对稀缺的语言上,EusParallel为提升翻译质量提供了宝贵的数据支持。
衍生相关工作
EusParallel数据集的发布催生了一系列相关研究工作,尤其是在低资源语言机器翻译领域。基于该数据集,研究人员开发了多种先进的翻译模型,并提出了针对低资源语言的优化策略。此外,EusParallel还为巴斯克语的语言学研究提供了数据支持,推动了巴斯克语与其他语言之间的对比研究。这些工作不仅丰富了机器翻译领域的研究成果,也为巴斯克语的保护和传承做出了贡献。
数据集最近研究
最新研究方向
在机器翻译领域,EusParallel数据集以其多语言并行文档级语料库的特性,为巴斯克语、英语和西班牙语之间的高质量翻译模型训练提供了重要资源。近年来,随着大语言模型如Meta-Llama-3-70B-Instruct的广泛应用,研究者们开始探索如何利用这些先进模型提升低资源语言的翻译质量。EusParallel通过将巴斯克语文档自动翻译为英语和西班牙语,为巴斯克语这一低资源语言的机器翻译研究开辟了新路径。当前的研究热点集中在如何优化翻译提示词(prompt)设计,以提高翻译的准确性和上下文适应性。此外,利用高性能计算资源如8xA100 80GB GPU和vLLM推理引擎,研究者们正在探索如何进一步提升翻译效率和质量。这一数据集的应用不仅推动了巴斯克语翻译技术的发展,也为其他低资源语言的机器翻译研究提供了宝贵的参考。
以上内容由AI搜集并总结生成
相关数据集

未查询到数据集